

بررسی نسل آینده چیپ های گرافیک انویدیا
در یک دهه اخیر، صنعت کارت های گرافیک رشد خیره کننده و قابل توجهی را تجربه کرده، که این هم به لطف رقابت دو غول صنعت تراشه ها یعنی AMD و انویدیا ممکن شده است. اگر به 5 سال پیش بازگردیم، شرکت اینتل به اندازه دو شرکت AMD و Nvidia همزمان درآمد سالیانه داشت در حالیکه امروز اینتل این جایگاه را به انویدیا واگذار کرده است و این انویدیا است که اکنون اندازه دو شرکت AMD و اینتل درآمد دارد. این تغییر در جایگاه نیز به سبب رویکرد جدیدی بوده است که انویدیا در سالهای اخیر اتخاذ کرده تا کارت های گرافیک را تبدیل به پردازنده های مناسب برای پردازش های سنگین مرتبط با یادگیری ماشین کند. به طوریکه دیگر ابر کامپیوترها هم مانند کامپیوتر خانگی گیمرها به کارت های گرافیک نیاز داشتند.
امسال انویدیا با دو میکرومعماری به استقبال طرفداران خود رفت که یکی از آنها در همایش GTC با نام رمز هاپر معرفی شد و دیگری کارت های توسعه یافته با نام رمز آدا لاولیس بودند که هنوز تا زمان انتشار این مطلب به صورت رسمی معرفی نشده اند. چیپ های میکرومعماری هاپر متناسب با فعالیت های سازمانی و برای پردازش های بسیار سنگین توسعه داده شده اند در حالیکه اعضای خانواده میکرومعماری آدا لاولیس قرار است کارت های رایج بازار و متناسب با کاربران عادی باشند.
انویدیا در پایان ماه فوریه امسال قربانی یک حمله سایبری جدی به مراکز اطلاعاتی و سرورهای خود شد که در آن اطلاعات زیادی هک شدند. این هک نه تنها برای انویدیا یک فاجعه بود، بلکه برای تمام شرکت های تراشه و امنیت ملی همه کشورهای “غربی” فاجعه به حساب میامد. در میان این داده های هک شده، مشخصات دقیق و داده های شبیه سازی کاملی برای پردازنده های گرافیکی نسل بعدی انویدیا یعنی هاپر و آدا وجود داشت. چیپ های توسعه داده شده با میکرومعماری هاپر که هم اکنون در حال ارسال به مشتریان سازمانی هستند ابتدا توسط Nvidia در GTC رونمایی شدند. مشخصاتی که انویدیا در همایش سالانه خود به کاربران ارائه داد دقیقاً با این نشت اطلاعات مطابقت داشت، اما میکرومعماری آدا، که به احترام اولین برنامه نویس جهان آدا لاولیس، اینگونه نامگذاری شده است، هنوز چند ماه دیگر تا رسیدن به دست مشتریان فاصله دارد.

در این مطلب من سعی می کنم تا اطلاعات درز کرده به بیرون را در ارتباط با میکرومعماری آدا لاولیس با دقت به شما بیان کنم و به نوعی با هم نسل بعدی پردازنده های گرافیکی انویدیا را مرور کنیم. این بررسی ها به همت وبسایت SemiAnalysis و همکاری او با برخی از متخصصین و اطلاعاتی است که در توییتر توسط افراد مختلف در ارتباط با موضوع منتشر شده است.

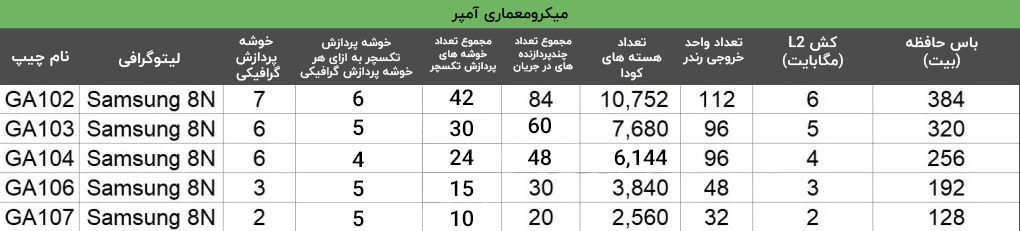
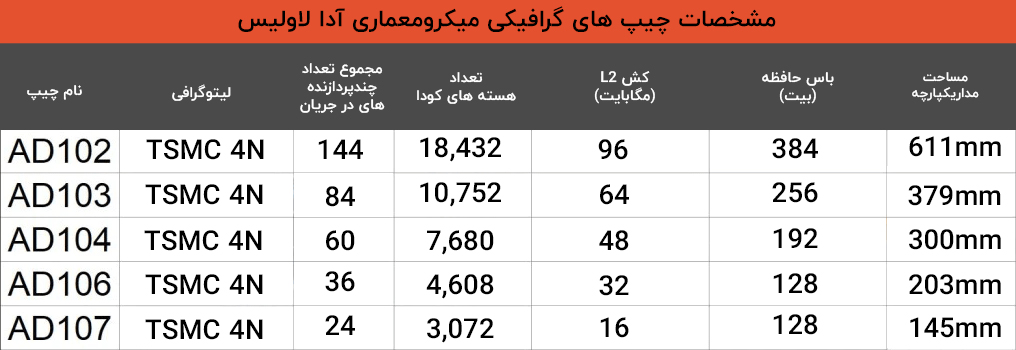
چیپ پرچم دار در معماری آدا، چیپ AD102 است که مساحت آن حدود 611.3 میلی متر مربع تخمین زده می شود. این یک جهش بزرگ نسبت به نسل قبلی یعنی چیپ GA102 محسوب می شود، چرا که در نسل جدید، هسته های کودا 70 درصد افزایش یافته اند. البته پهنای باس حافظه همان 384 بیت ثابت باقی مانده است ولی ما انتظار داریم سرعت حافظه تا حدود 21 گیگابیت در ثانیه بهبود یابد. با وجود افزایش سرعت حافظه، ظاهراً انویدیا به همین موضوع بسنده نکرده و برای نسل بعد پردازش های فوق سنگین، حافظه کش L2 96مگابایتی فوق سریعی برای چیپ تدارک دیده که به نسبت 6 مگابایت کش نسل قبل 16 برابر افزایش داشته!
شاید جالب باشد بدانید این حجم 96 مگابایتی دقیقاً همان مقدار کش L2 در نظر گرفته شده از سوی AMD برای چیپ های Navi 22 می باشد که AMD آن را Infinity Cache نام گذاری کرده است.
البتهInfinity Cache شرکت AMD یک کش از نوع L3 محسوب می شود، اما با وجود تفاوتهای سلسله مراتبی و نوع نامگذاری کش بین دو فروشنده، انتظار داریم روند کلی نرخ رشد عملکرد یکسان باشد. در مورد AMD، نرخ برخورد کش در نسبت ابعادی 1080p تقریباً 78درصد ، در ابعاد 1440p حدوداً 69درصد و نهایتاً در ابعاد 4K حدوداً 53درصد است. نرخ برخورد کش اندازه گیری تعداد درخواست های محتوایی است که یک کش می تواند با موفقیت پر کند، در مقایسه با تعداد درخواست هایی که دریافت می کند. این نرخ برخورد بالای اطلاعات با کش به کاهش نیاز به پهنای باند حافظه کمک می کند. اگر کش L2 حجیم انویدیا هم به روش مشابهی عمل کند، علیرغم افزایش ناچیز در پهنای باند حافظه در این نسل، کش L2 در نظر گرفته شده به تغذیه AD102 کمک زیادی خواهد کرد. پرچم دار میکرومعماری آدا احتمالاً باید با 24 گیگابایت GDDR6X ارائه شود، اما تا زمان عرضه باید صبر کنیم تا ببینیم پیش بینی هایمان درست از آب درمیاید یا خیر.

چیپ بعدیAD103 است که به عنوان یک پردازنده با مساحت مدار یکپارچه ای حدود 379.69 میلی متر مربعی بسیار جالب به نظر می رسد. در مقایسه با AD102، یک تنزل رتبه بزرگ است. این تفاوت را شاید بتوان بزرگترین شکاف در چیپ های اخیر بین دو چیپ با فاصله یک پله دانست به طوریکه چیپ پرچم دار، 70 درصد هسته های کودای بیشتری نسبت به یک پله پایین تر از خود دارد.
نکته جالب دیگر این است که تعداد هسته های کودا این نسل در چیپ AD103 دقیقاً مشابه نسل فعلی یعنی GA102 است. پهنای باس حافظه 256 بیتی این چیپ هم بسیار کوچکتر از گذرگاه 384 بیتی AD102 است. از سوی دیگر کارت های گرافیکی که قرار است مبتنی بر چیپ AD103 ساخته شوند حداکثر 16 گیگابایت حافظه خواهند داشت، اما پیش بینی می شود نسخههای کوچکتر هم توسعه داده شوند. علیرغم اینکه پهنای باند حافظه بسیار کمتر از GA102 است، گنجاندن یک حافظه نهان 64 مگابایتی L2، همچنان به این GPU اجازه می دهد تا نیاز زیادی به حافظه پرسرعت برای بهبود عملکرد نداشته باشد.
با توجه به اینکه انویدیا از یک فناوری فرآیند تولید جدید تحت عنوان 4N برای چیپ های جدید استفاده می کند، انتظار داریم که این چیپ ها بتوانند کلاک هسته بالاتری نسبت به GA102 داشته باشند. افزایش کلاک هسته، همراه با پیشرفت های معماری به AD103 اجازه می دهد تا عملکرد بسیار بهتری حتی نسبت به پرچمدار نسل فعلی یعنی RTX 3090 Ti داشته باشد، البته اگر این چیپ ها با مصرف انرژی بالا روی کامپیوترهای شخصی بیایند! توجه به این نکته مهم است که GA103 هرگز روی دسکتاپ نیامد و فقط در لپ تاپ های رده بالا مورد استفاده قرار گرفت، بنابراین این اتفاق ممکن است در نسل Ada نیز تکرار شود.

چیپ بعدی AD104 است که مساحت آن حدود 300.45 میلیمتر مربع تخمین زده میشود و به دلیل عملکرد و مقرون به صرفه بودن، گزینه ای دوس داشتنی در خط تولید Ada محسوب می شود. باس 192 بیتی این چیپ به ماکزیمم حافظه 12 گیگابایتی منجر میشود که به نظر من ظرفیت کافی را دارد. از سوی دیگر، چیپ 104 نسل جدید، عملکردی مشابه با چیپ نسل قبلی 102 دارد که اگر روند ذکر شده در بالا برای چیپ های قوی تر این نسل، برای این چیپ هم ادامه پیدا کند، نسبت هزینه به عملکرد خیلی عالی می شود. بطوریکه در واقع، ممکن است این چیپ از RTX 3090 هم با کلاک مناسب، عملکرد بهتری ارائه دهد در حالی که یک چیپ میان رده در نسل بعد محسول می شود. همچنین این چیپ بدون حافظه های GDDR6X و با کمی کلاک پایین تر می تواند گزینه ایده آلی برای استفاده در لپ تاپ ها باشد.

یک پله پایین از AD104، چیپ AD106 قرار دارد که با مساحت مداریکپارچه ای حدود 203.21 میلی متر مربع احتمالاً یکی از بالاترین حجم را در خط تولید خواهد داشت زیرا همواره چیپ های 106 بالاترین حجم را در نسل های پاسکال، تورینگ و آمپر به خود اختصاص داده بودند. با توجه به باس 128 بیتی، احتمالاً کارت های گرافیک توسعه داده شده با این چیپ عمدتاً با 8 گیگابایت حافظه عرضه شوند. از لحاظ عملکردی، انتظار داریم که این چیپ عملکردی مشابه GA104 داشته باشد، که در کارت RTX 3070 Ti مورد استفاده قرار گرفته بود. البته با توجه به اینکه این چیپ تنها 3 عدد GPC در مقابل 6 عدد GPC در GA104 دارد، ممکن است این فرض کمی بیش از حد خوش بینانه باشد. 32 مگابایت حافظه نهان L2 نیز همانند چیپ های قوی تر اتکای چیپ به حافظه را اندکی کاهش می دهد.
قبل از اینکه به سراغ کوچکترین عضو نسل جدید پردازنده های گرافیکی انویدیا یعنی چیپ AD107 برویم، لازم است کمی پیش زمینه ارائه دهیم. داده های قرار داده شده در توییتر توسط کسانی که به اطلاعات سری انویدیا دسترسی داشته اند، متأسفانه اندازه کش این چیپ را مشخص نمی کند. در چیپ های قبلی ما همان 16 مگابایت را به ازای هر کنترلر حافظه 64 بیتی فرض کردیم ولی در AD107 این موضوع چندان منطقی به نظر نمی رسد چرا که تعداد خوشه های پردازش گرافیکی این چیپ و باس حافظه یکسان باقی مانده است در حالیکه خوشه های پردازش بافت در این چیپ فقط به 4 عدد کاهش یافته اند. با این روند اگر حافظه نهان L2 ثابت بماند، اندازه قالب باید از 203.21 میلی مترمربع در چیپ AD106 به 184.28 میلی متر در چیپ AD107 کاهش بیابد که خب رقم تفاوت بسیار کمی برای دو چیپ با رده بندی متفاوت خواهد بود.

به همین دلیل ما فرض کردیم که باید این بین رابطه ای مشابه با چیپ های TU116 و TU106 در نسل تورینگ وجود داشته باشد. چیپ های TU116 دارای یک FBP با 0.5 مگابایت کش L2 به جای 1 مگابایت در چیپ های TU10x بودند. اگر همان الگوی کاهش 50% در کش L2 را در هر FBP برای چیپ جدید اعمال کنیم، مساحت چیپ AD107 در نهایت 145.54 میلی متر مربع خواهد بود که بسیار معقول تر به نظر می رسد.

با این فرضیات، اینگونه به نظر می رسد که چیپ AD107 یک چیپ موبایلی عالی باشد که برای 8 لاین PCIe تنظیم شده است؛ چرا که تعداد بیشتری از آنها نیازی نیست و انویدیا معمولاً چیپ های پایین رده خود را به این تعداد لاین محدود می کند. عملکرد این چیپ هم با توجه به پیش بینی های ما قوی ترین چیپ های گرافیکی ادغام شده یا همان آنبورد اینتل را به راحتی شکست می دهد در حالیکه به حدی ارزان خواهد بود که در برخی از لپ تاپ های ارزان نیز شاهد حضور آن باشیم.
به طور کلی میکرومعماری آدا ترکیب بسیار جالبی است. در بالای لیست، عملکرد و البته مصرف انرژی به شکل قابل توجهی کاملاً افزایش یافته است. از سوی دیگر مساحت چیپ AD102 اندازه چیپ GA102 می باشد اما با فرق اینکه در میکرومعماری جدید از تکنولوژی فرایند تولید 4N جدید شرکت TSMC به جای فناوری 8N شرکت سامسونگ استفاده شده است که کمک می کند تا تعداد قابل توجهی ترانزیستور بیشتر بر روی بردی با مساحت یکسان قرار بگیرد. افزایش چگالی چینش ترانزیستورها در تکنولوژی فرآیند تولید TSMC N4 هم نسبت به فناوری 8 نانومتری سامسونگ بسیار زیاد است که هزینه را توجیه می کند.
مسئله قابل توجه دیگر قیمت هاست. با توجه به اینکه فرآیند تولید جدید ارزان تر از فرآیند قبلی برای انویدیا تمام می شود احتمال افزایش ارزش خرید در این نسل بسیار بالاست.
مسئله دیگری که نظر مارا جلب کرد، مسئله مصرف انرژی بسیار بالای این نسل است. انویدیا احتمالاً برای هر چیپ مشابه آنچه نسل قبل انجام میداد، برق پمپاژ میکند. در واقع، میتوانیم تصور کنیم که برای مثال مصرف انرژی چیپ AD104 چیزی مشابه کارت 3080 باشد در حالیکه چیپ AD106 حدوداً مانند کارت 3070 خواهد بود. و البته از همه مهمتر چیپ پرچم دار یعنی AD102 قرار است در مسئله مصرف انرژی رکورد شکن باشد.
در مرحله بعد، باید نحوه رسیدن به این تخمین از مساحت چیپ را بررسی کرد. اولین گام در تجزیه و تحلیل مساحت، جمع آوری اطلاعات مربوط به تغییرات معماری در مورد آدا و مقایسه آنها با آمپر بود. ما افزایش 10 درصدی در اندازه SMها(Streaming Multiprocessor) را در نظر گرفتیم؛ هرچند مطمئن نیستیم که تغییرات معماری SM چه چیزهایی را در بر خواهد گرفت اما به طور بالقوه این تغییرات میتواند شامل یک کش L1 با ظرفیت 192 کیلوبایت و هستههای تانسور باشند. بیشترین احتمال تغییر در ذهن ما اضافه شدن یک هسته رهیابی پرتو جدید نسل سوم است. جالب است بدانید نشت اطلاعات فاش کرده است که فناوری گران قیمت NVLink به طور کامل از این سری حذف شده است که نشان میدهد انویدیا قرار نیست اعضای خانواده میکرومعماری Ada را برای مراکز داده و برنامههای سه بعدی سازی حرفهای توسعه دهد. همچنین ما انتظار داریم که چیپ های جدید از درگاه PCIe 5.0، یک کنترلر حافظه بهتر برای حافظه های GDDR6X، درگاه DisplayPort 2.0 و البته دو قابلیت Nvidia NVDEC و Nvidia NVENC بهبود یافته نسبت به نسل پیش بهره ببرند.

بزرگترین تغییر آدا البته همانطور که گفته شد در کش L2 است. به نظر میرسد انویدیا به جای یک کش L2 کم حجم، از روی دست رقیبش نگاه کرده و از کشهای بسیار بزرگتری در سراسر برد استفاده کرده است که کمک می کند تا بدون نیاز به جهشی انقلابی در صنعت حافظه ها بتوان عملکرد نسل پیش را به شکل باورنکردنی افزایش داد.

با استفاده از بلوکهای به کار رفته در ساخت چیپ GA102، به مساحت مدار 1629.60 میلیمتر مربع برای این پردازنده گرافیکی فرضی با پیکربندی مشابه چیپ AD102، اما ساخته شده با فرآیند تولید 8 نانومتر میرسیم. چیزی که بلافاصله متوجه خواهید شد این است که کش L2 به شکل عجیبی بزرگ است. شرکت AMD بر روی پردازنده های گرافیکی سری Navi 21 خود مقدار کش L3 بیشتری دارد ولی از لحاظ ابعاد فیزیکی کش انویدیا در برد فضای بیشتری را اشغال کرده است. البته ممکن است فکر کنید، چیپ AMD با تکنولوژی فرآیند تولید متراکم تری(N7) ساخته شده است، اما این تنها بخش کوچکی از پازلی است که باید آن را حل کنید.
چیپ GA102 از 48 قطعه 128 کیلوبایتی حافظه SRAM با 1 مگابایت کش L2 به ازای هر کنترلر حافظه 64 بیتی یا پارتیشن بافر فریم (FBP) استفاده می کند. از طرف دیگر چیپ GA100 از 80 قطعه 512 کیلوبایتی SRAM استفاده می کند. همانطور که در مقایسه با کش L2 AMD دیده می شود، به نظر می رسد این برش های بزرگ تر چگالی را بسیار بهبود می بخشند. افزایش چگالی GA100 بسیار بیشتر از کاهش ابعاد به واسطه تکنولوژی فرآیند تولید جدیدتر است. همین اثر را میتوانید در کش L3 اینفینیتی کش AMD هم ببینید.
در حالی که طراحان AMD در بسیاری از المان های طراحی به خوبی انویدیا نیستند، اما ما معتقدیم که آنها بدون شک در برخی زمینه ها مانند کش و بسته بندی بهتر هستند. همانطور که در Infinity Cache نشان داده شده است، طراحان شرکت AMD در ساخت کش های بسیار متراکم با کارایی بالا برای چیپ های گرافیکی بسیار خوب عمل می کنند. در واقع، در تخمینهای نهایی ما از مساحت مداریکپارچه، 96 مگابایت کش L2 انویدیا هنوز به اندازه 96 مگابایت L3 Infinity Cache شرکت AMD نیست.

صرف نظر از کوچک شدن تکنولوژی فرآیند تولید از سامسونگ 8 نانومتری به TSMC 4 نانومتری، میتوان با اطمینان گفت این موضوع به تنهایی نمی تواند بلوک های تشکیل دهنده GA102 را به مساحت معقول برساند. در عوض، در طراحی کش نیاز به بازسازی معماری وجود داشت. اطلاعات نشت کرده در فضای مجازی به ما می گوید که اکنون 16 مگابایت L2 به ازای هر کنترل کننده حافظه 64 بیتی در FBP برای AD102 وجود خواهد داشت. به همین دلیل تخمین می زنیم که انویدیا به سوی 48 برش، 2048 کیلوبایتی SRAM خواهد رفت.
با این پیکربندی کش، می توانیم پهنای باند کش را با این ارقام محاسبه کنیم. چیپ های AMD در میکرومعماری Navi21 دارای پهنای باند حدوداً 1.99ترابایت بر ثانیه ای در کش Infinity Cache هستند که با فرکانس 1.94 گیگاهرتز فعالیت می کنند. اگر فرض کنیم کش انویدیا هم با همان فرکانس 1.94 گیگاهرتزی در AD102 کار میکند، در این صورت آنها میتوانند به رقم خیره کننده 5.96 ترابایت بر ثانیه پهنای باند در کش L2 خود دست یابند. البته کلاک کش در محصولات نهایی ممکن است متفاوت باشد اما ما انتظار داریم این رقم برای چیپ های میکرومعماری آدا در حدود 2.25 گیگاهرتز باشد که به مراتب از کلاک کش اینفینیتی AMD بیشتر است. البته AMD هم در نظر دارد در RDNA3 روی دسکتاپ سرعت کلاک کش را به بالاتر از 2.5 گیگاهرتز برساند پس احتمال اینکه انویدیا هم برای نسل جدید خود چنین کاری کرده باشد بسیار محتمل است. در حقیقت می توان گفت انویدیا تراکم و ابعاد فیزیکی کش را قربانی سرعت بیشتر آن ها کرده است و اگر میخواست به تراکمی مشابه محصولات AMD برسد مجبور بود از برش های 8 تا 16 مگابایتی استفاده کند که همین موضوع ممکن بود کلاک کش را حتی به پایین تر از چیزی که در آمپر شاهد آن بودیم برساند.

ما به تخمینهایی رسیدیم که معماری متفاوت کش در چیپ های جدید انویدیا چه تأثیری بر روی مساحت نهایی مدار یکپارچه این چیپ ها خواهد داشت. سپس فاکتورهای کوچک شدن تکنولوژی فرآیند تولید را ابتدا برای N7 TSMC و سپس برای TSMC N4 اعمال کردیم. به نظر می رسد SRAM از تقسیم 60:40 SRAM نسبت به دیگر بخش های محاسباتی مداریکپارچه تبعیت می کند، که به کاهش ابعاد فیزیکی SRAM در محاسبات ما انجامیده است. ما یک افزایش 10 درصدی را برای چندپردازنده های در جریان(SM) هم اعمال کردیم تا تغییرات معماری جدید را هم در بر بگیرد.
در نهایت، ما بخشهای آنالوگ چیپ را نسبت به گذشته یکسان نگه داشتیم زیرا کوچک شدن آن بسیار اندک است، اما این بخشها با ارتقاءهای احتمالی مانند PCIe 5.0، سرعت حافظه GDDR6X و DisplayPort 2.0 ممکن است کمی افزایش را داشته باشیم که با حذف شدن NVLink آن افزایش جزئی هم برابر می شود و می شود گفت در پایان به حدود 611 متر مربع می رسیم که این به موضوع به طور مستقل با آنچه کاربر دیگری تحت عنوان kopite7kimi در مورد مساحت مدار بیان کرده است، مطابقت دارد.
به طور کلی، به نظر نمیرسد که میکرومعماری Ada Lovelace از نظر بنیادی از معماری قبلی یعنی Ampere انحراف زیادی داشته باشد، اما تغییراتی مانند هسته های بهبود یافته رهیابی پرتو، رمزگذارهای بهبودیافته و حافظه کش L2 بزرگتر را برای چیپ های خود در نظر گرفته است که در نهایت عملکرد را به میزان قابل توجهی افزایش و البته هزینه ها را کاهش میدهد. حتی با وجود اینکه بر روی یک تکنولوژی فرآیند تولید گرانتر مبتنی بر TSMC N4 قرار دارد.
شایعات در مورد شرکت AMD اما به عملکرد بسیار بالا و همچنین هزینه بالا برای چیپ های پرچم دار این شرکت اشاره می کنند. همه منتظر تراشه های Navi33 آنها هستند که باید در جایی بین دو چیپ AD104 و AD106 قرار بگیرد. اطلاعات نشت شده همچنین نشان می دهد که در این نسل AMD رقیب خوبی برای انویدیا در بازار انبوه خواهد بود؛ هرچند که در حال حاضر AMD به شدت در عملکرد رهیابی پرتو عقب است و فقدان بسیاری از ویژگیهای نرمافزاری هم مثل DLSS و Broadcast به رقابت آنها لطمه میزند، اما ما معتقدیم که این رقابتی ترین نسل پردازنده های گرافیکی در یک دهه اخیر خواهد بود.
قیمت پردازندههای گرافیکی هم به سرعت در حال کاهش است و خبر های خوبی از انگلیس و برخی دیگر از کشورهای توسعه یافته می رسد. موجودی کارت های گرافیک در بازارها بیشتر شده و تولید کنندگان به دنبال پر کردن خلا های بین نیاز و تأمین هستند. امیدوارم از مطلب بنده لذت برده باشید.







دیدگاه خود را ثبت کنید
تمایل دارید در گفتگوها شرکت کنید؟در گفتگو ها شرکت کنید.